How I Reduced Cloud Costs by 40%: A FinOps Case Study
Visibility before optimization. Ownership before tooling. Architecture before discounts.
Iulian Mihai
Principal Cloud Architect & AI Innovation Leader
The first time I was asked to “look into cloud costs,” the environment was already past polite concern.
Monthly spend had doubled in under a year. No single team felt responsible. Finance had dashboards. Engineering had explanations. Leadership had lost trust in both.
This wasn't a startup that moved too fast. It was a large Azure estate spanning dozens of subscriptions, multiple regions, regulated workloads, and a governance model that looked correct on slides.
What followed wasn't a cost-cutting exercise. It was a FinOps correction — architectural, operational, and cultural.
The outcome was a sustained cost reduction of just over 40%, without shutting systems down or slowing delivery.
The real problem wasn't waste. It was blindness.
Most organizations assume cloud cost problems come from waste.
- Idle VMs
- Oversized databases
- Forgotten environments
Those exist, but they're rarely what drives major overruns at scale. The real problem is structural blindness.
Teams don't understand what they're paying for, why they're paying for it, or which architectural decisions created the bill.
Azure Cost Management was enabled. Budgets existed. Tags were defined. None of that helped. Because the cost model didn't match how the platform was actually used.
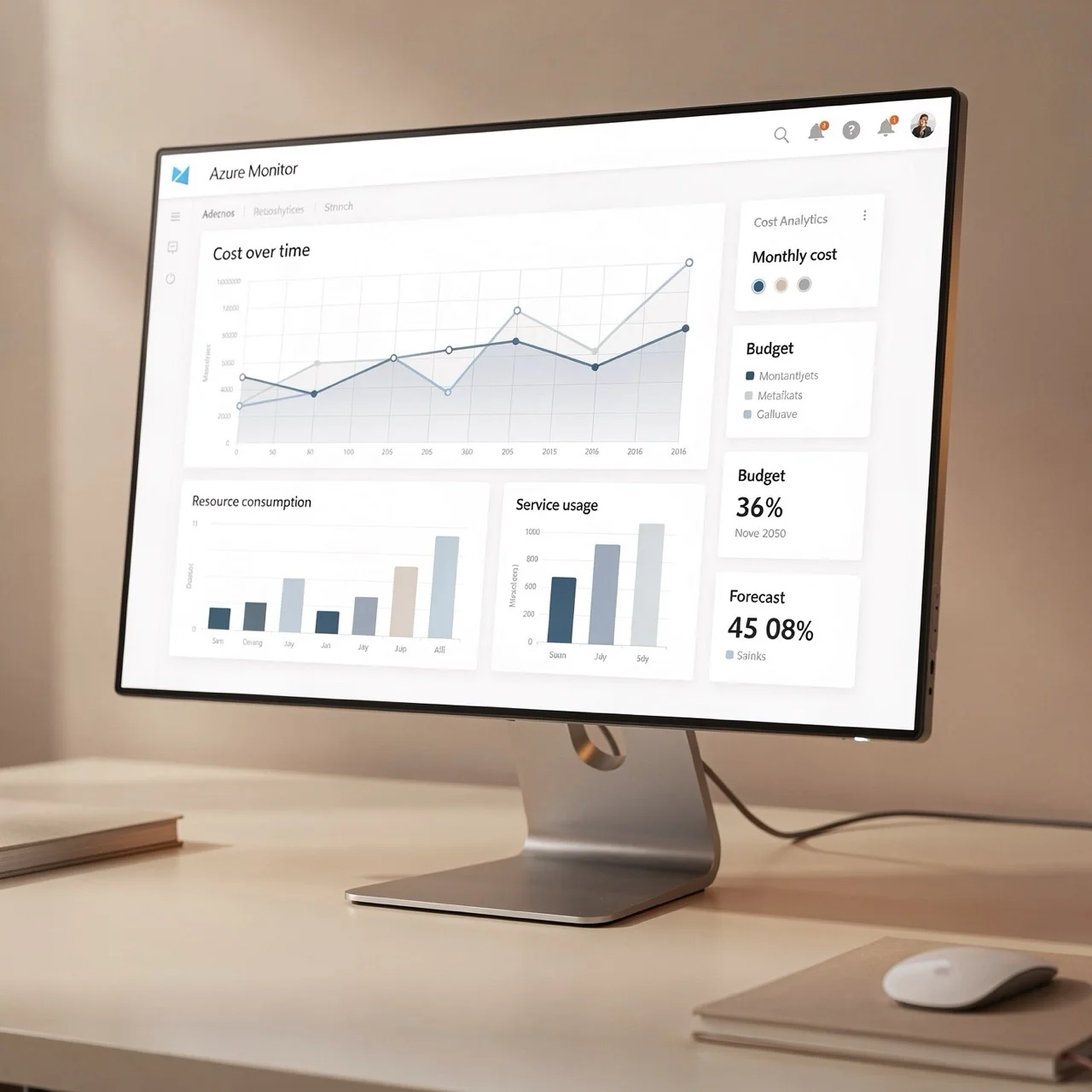
Custom Azure Workbooks changed the conversation
The turning point wasn't an optimization recommendation. It was visibility.
I built a set of custom Azure Monitor Workbooks that mapped every billable resource across all subscriptions into a single, navigable view. Not finance dashboards — architectural dashboards.
We visualized:
- Cost by subscription, resource group, and service family
- Cross-subscription shared services consumption
- Region-level cost concentration
- Growth trends per workload, not per invoice line
- Egress-heavy resources correlated with network flow logs
For the first time, architects could point at a dashboard and say:
“This is the service. This is the cost. This is why.”
That moment mattered — because FinOps only works when cost becomes an architectural signal, not a finance report.
Cost allocation failed before optimization even started
Once visibility improved, the next issue surfaced immediately: ownership.
Subscriptions were aligned to environments, not products. Shared services lived in “platform” subscriptions consumed by everyone and owned by no one.
From a finance perspective, nearly a third of spend was unallocated. From an engineering perspective, it was invisible.
We fixed this structurally. Subscriptions were reorganized around ownership and accountability, not deployment convenience. Shared services were split by consumption pattern. Some teams pushed back. Finance didn't.
Once cost boundaries matched organizational boundaries, conversations changed. Optimization finally had a target.
The Well-Architected Framework was the guardrail, not the goal
At this point, optimization could have become tactical. Instead, I anchored every major decision in the Azure Well-Architected Framework — specifically the Cost Optimization and Reliability pillars.
Not as a checklist. As a decision filter.
Every optimization had to answer:
- Does this reduce cost without increasing operational risk?
- Does it improve predictability?
- Does it align with how this workload is supposed to behave long-term?
This ruled out several “obvious” savings. Some workloads were intentionally over-provisioned because availability mattered more than efficiency. Others were allowed to scale aggressively because business demand justified it.
FinOps is not about minimizing spend. It's about aligning spend with intent.
Reserved Instances only worked after architecture was stable
The organization had avoided Reserved Instances with a familiar argument: “We're not stable enough.”
That was partially true. The other part was lack of trust in the data.
We started with services that were architecturally constrained. Azure SQL Database first: predictable workloads, known service tiers, and compliance constraints that ruled out aggressive autoscaling.
We committed at the service tier level, not the instance level. This avoided coupling reservations to deployment mistakes.
Two billing cycles later, the savings were obvious. More importantly, confidence improved. Only then did we extend reservations to compute — starting with infrastructure components contractually guaranteed to exist.
Reservations don't fail because workloads change. They fail because organizations don't know which workloads are allowed to be stable.
Storage was quietly bleeding money
Blob storage rarely triggers alarms. It grows slowly. It's cheap per unit. And it's almost never reviewed.
In this environment, diagnostics logs, traces, and exports had accumulated for years. Lifecycle policies existed, but inconsistently.
We standardized retention through Azure Policy, not manual configuration. Logs older than 30 days moved to cool storage. Older than 90 to archive.
Some teams objected, citing “future investigations.” We tested restores. They worked. The objections stopped.
This single change delivered double-digit percentage savings in storage costs, with zero operational impact.
Custom Python filled the gaps Azure tooling doesn't cover
Azure tooling is good. It's not complete.
We used custom Python scripts to close the gaps:
- Correlating Cost Management exports with Azure Resource Graph
- Identifying orphaned resources not visible in standard reports
- Flagging long-running PaaS resources with no traffic
- Detecting anomalous spend spikes across billing periods
These scripts ran as scheduled jobs, feeding results back into Workbooks.
This wasn't about building a new platform. It was about stitching together signals Azure doesn't connect for you.
Principal-level FinOps often looks like glue code.
Autoscaling without limits is deferred over-provisioning
AKS clusters were configured to autoscale aggressively. They scaled up. They rarely scaled down.
From an SRE perspective, this felt safe. From a FinOps perspective, it was uncontrolled risk.

We introduced hard ceilings, agreed with engineering leads and reviewed quarterly. Clusters still had headroom — but nodes actually disappeared at off-peak hours.
Autoscaling without explicit limits is not optimization. It's just delayed waste.
Network costs were the least understood and most expensive
Egress was the real surprise. Traffic patterns had evolved. Architectures hadn't.
Cross-region calls, data replication, and “temporary” integrations had become permanent. No one owned the full path.
Using Network Watcher flow logs combined with cost exports, we mapped traffic flows manually. It wasn't elegant. It was necessary.

In one case, moving a service into the same region as its consumers reduced costs more than any compute optimization we had done.
This matters especially in EU environments, where region choice is constrained by regulation and latency expectations.
FinOps worked once accountability became social
We didn't create a FinOps team. We embedded FinOps into existing roles.
- Product owners owned budgets
- Architects owned cost models
- Platform teams owned shared services
Monthly cost reviews became factual, short, and non-negotiable. No blame — just numbers and decisions.
Once teams understood that cost visibility was permanent, behavior changed. That's when the 40% reduction became durable.
What I'd do differently
I would start earlier.
Most FinOps initiatives begin when leadership is already frustrated. That makes everything harder.
I would also introduce cost modeling during design reviews, not after deployment. And I would be explicit about this truth:
FinOps is not about saving money. It's about making cost a first-class architectural constraint.
Once teams accept that, optimization stops feeling like punishment.
The pattern that emerged
Every successful cost reduction I've led followed the same pattern:
- Visibility before optimization
- Ownership before tooling
- Architecture before discounts
Cloud costs don't spiral because engineers are careless. They spiral because systems grow faster than accountability.
Fix that, and a 40% reduction isn't aggressive. It's just what happens when an Azure estate is finally operated like a platform, not a credit card.
If you want a role-specific view of how I approach FinOps engagements, see FinOps for CFOs.
💡Want cost visibility that engineers trust?
If your Azure spend is growing faster than accountability, I can help you build cost visibility that maps spend to architecture — and turn FinOps into a durable operating rhythm.
Tags
Need Help with Your Multi-Cloud Strategy?
I've helped Fortune 500 companies design and implement multi-cloud architectures that deliver real business value. Let's discuss how I can help your organization.
Book a ConsultationNu știi de unde să începi?