What is RAG?
Retrieval-Augmented Generation (RAG)combines the power of large language models with your organization's specific knowledge. Instead of relying solely on the LLM's training data, RAG retrieves relevant documents from your data and uses them to generate accurate, contextual responses.
🏗️ RAG Architecture Overview
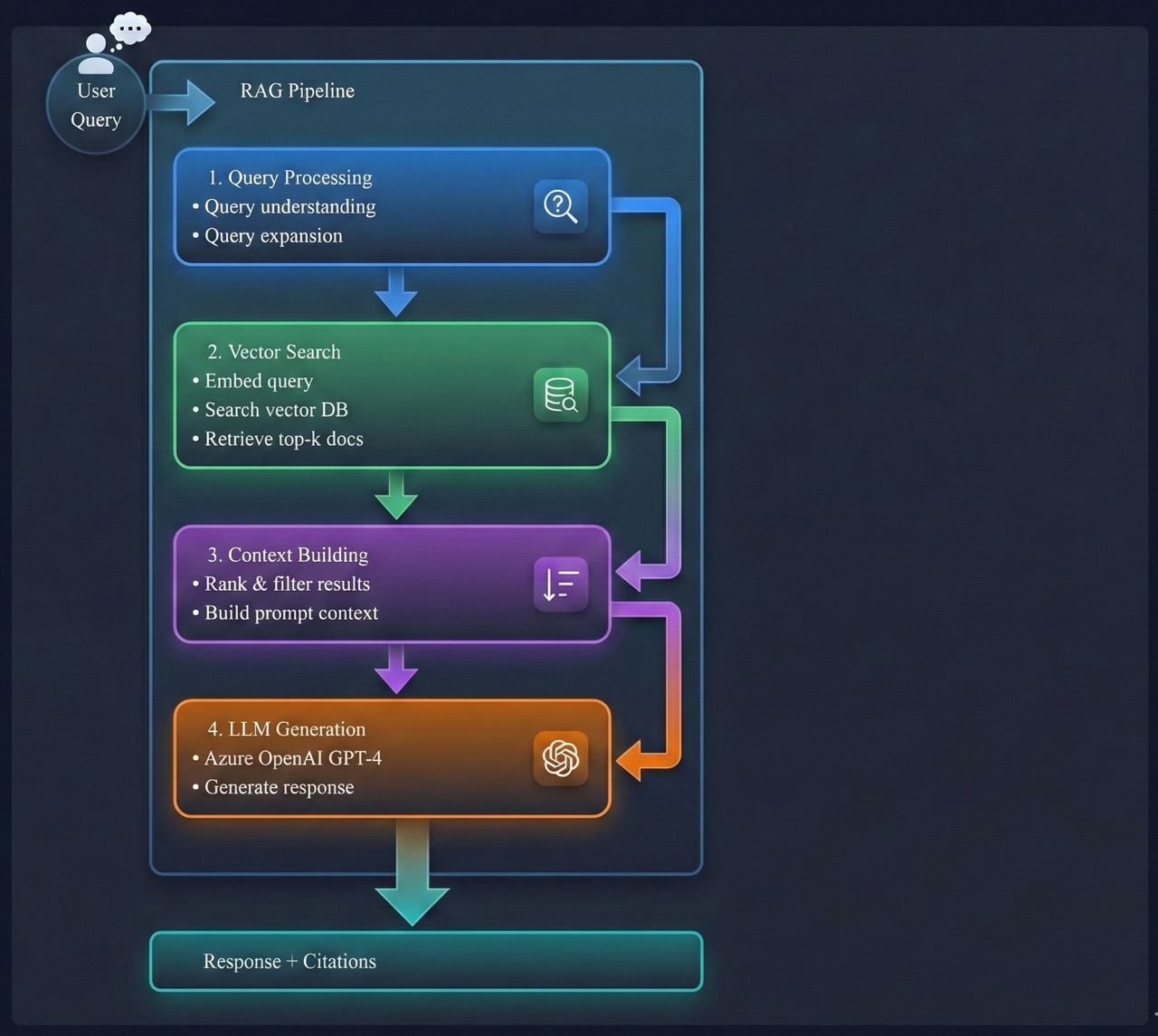
📦 Phase 1: Data Preparation (Weeks 1-2)
Data Source Inventory
- Identify all knowledge sources (docs, wikis, databases, APIs)
- Assess data quality and freshness
- Define access controls and permissions
- Plan data refresh/sync strategy
Chunking Strategy
| Strategy | Best For | Chunk Size |
|---|---|---|
| Fixed-size | Simple docs, FAQs | 500-1000 tokens |
| Semantic | Long-form content | Variable |
| Hierarchical | Technical docs | Parent/child |
| Sentence-based | Q&A, support | 3-5 sentences |
🔧 Phase 2: Infrastructure Setup (Weeks 2-3)
Azure Services Required
- Azure OpenAI: GPT-4/GPT-4o for generation, text-embedding-ada-002 for embeddings
- Azure AI Search: Vector search with hybrid (keyword + semantic) capabilities
- Azure Blob Storage: Document storage with indexer integration
- Azure Functions / Container Apps: Orchestration layer
- Azure Key Vault: Secrets and API key management
Architecture Decision: Vector Database
Azure AI Search (Recommended)
- ✅ Native Azure integration
- ✅ Hybrid search built-in
- ✅ Managed service
- ✅ Security/compliance ready
Alternatives
- • Pinecone (managed, multi-cloud)
- • Weaviate (open-source)
- • Qdrant (open-source)
- • PostgreSQL + pgvector
🚀 Phase 3: RAG Pipeline Development (Weeks 3-5)
Core Pipeline Components
# Simplified RAG Pipeline (Python/LangChain)
from langchain.embeddings import AzureOpenAIEmbeddings
from langchain.vectorstores import AzureSearch
from langchain.chat_models import AzureChatOpenAI
from langchain.chains import RetrievalQA
# 1. Initialize embeddings
embeddings = AzureOpenAIEmbeddings(
deployment="text-embedding-ada-002",
api_key=os.environ["AZURE_OPENAI_KEY"]
)
# 2. Connect to vector store
vector_store = AzureSearch(
azure_search_endpoint=os.environ["SEARCH_ENDPOINT"],
index_name="knowledge-base",
embedding_function=embeddings
)
# 3. Initialize LLM
llm = AzureChatOpenAI(
deployment_name="gpt-4",
temperature=0
)
# 4. Create RAG chain
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vector_store.as_retriever(k=5),
return_source_documents=True
)Prompt Engineering Best Practices
- Use system prompts to define persona and constraints
- Include explicit instructions to cite sources
- Add guardrails: "If unsure, say 'I don't know'"
- Test with adversarial queries (prompt injection)
🔒Phase 4: Security & Governance (Ongoing)
Security Checklist
- ☑️ Private endpoints for all services
- ☑️ Managed identities (no keys in code)
- ☑️ Row-level security on documents
- ☑️ Content filtering enabled
- ☑️ Audit logging to Log Analytics
Governance Checklist
- ☑️ Data classification policy
- ☑️ PII detection and redaction
- ☑️ Usage monitoring and quotas
- ☑️ Model version management
- ☑️ Responsible AI guidelines
📊 Success Metrics
| Metric | Target | How to Measure |
|---|---|---|
| Answer Accuracy | >85% | Human evaluation, golden dataset |
| Retrieval Precision | >70% | Relevant docs in top-5 |
| Response Latency | <3s | P95 end-to-end time |
| User Satisfaction | >4/5 | Thumbs up/down, surveys |
| Hallucination Rate | <5% | Factual grounding checks |
⚠️ Common Pitfalls
- ❌ Poor chunking: Too large = irrelevant context. Too small = missing context.
- ❌ Ignoring metadata: Document dates, authors, categories improve retrieval.
- ❌ No evaluation: You can't improve what you don't measure.
- ❌ Skipping security: RAG can leak sensitive data if not secured properly.